# # /etc/fstab # Created by anaconda on Mon Aug 5 20:47:30 2019 # # Accessible filesystems, by reference, are maintained under '/dev/disk' # See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info # /dev/mapper/centos-root / xfs defaults 0 0 UUID=c79e1466-7fc4-4434-863f-d1f6b1c2f3e1 /boot xfs defaults 0 0 /dev/mapper/centos-swap swap swap defaults 0 0 UUID=1ce3f41e-cd87-4e86-b069-fd1bb6d744d5 /data xfs defaults 0 0
SYS@orcl> select value from v$diag_info where name ='Diag Trace';
VALUE ------------------------------------------------------------------------------------------------------------------------ /u01/app/oracle/diag/rdbms/orcl/orcl/trace
cd /u01/app/oracle/fast_recovery_area/orcl mv control02.ctl control02.ctl.bak cp /u01/app/oracle/oradata/orcl/control01.ctl /u01/app/oracle/fast_recovery_area/orcl/control02.ctl
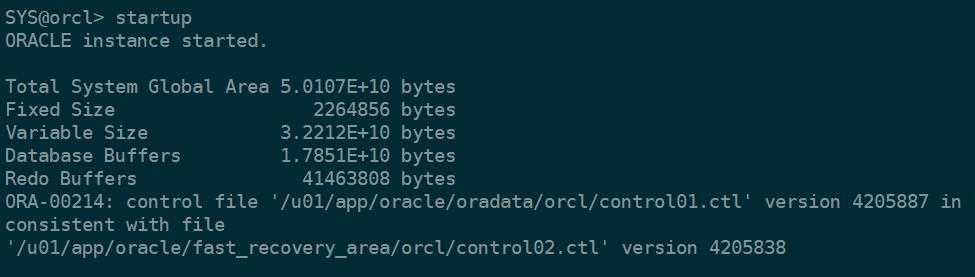
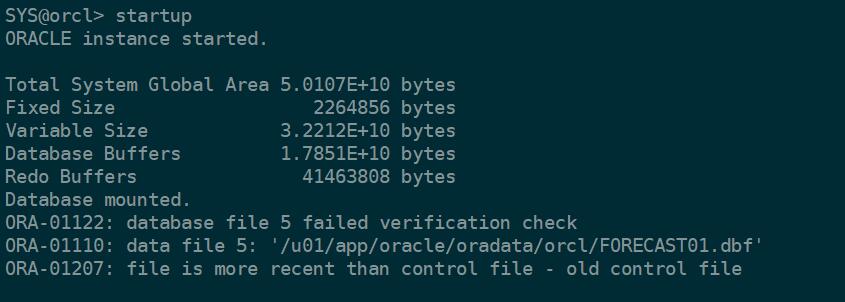
再次启动,出现如下错误,如图所示,可以启动的mount阶段,数据库无法open。
1 2 3 4 5
SYS@orcl> alter database open; alter database open * ERROR at line 1: ORA-01589: must use RESETLOGS or NORESETLOGS option for database open
1 2 3 4 5 6
SYS@orcl> alter database open resetlogs; alter database open resetlogs * ERROR at line 1: ORA-01194: file 1 needs more recovery to be consistent ORA-01110: data file 1: '/u01/app/oracle/oradata/orcl/system01.dbf'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19
SYS@orcl> select v1.group#, member, sequence#, first_change# from v$log v1, v$logfile v2 where v1.group# = v2.group#;
SYS@orcl> recover database using backup controlfile until cancel; ORA-00279: change 395590635 generated at 02/06/2021 16:09:01 needed for thread 1 ORA-00289: suggestion : /u01/app/oracle/oradata/orcl/archivelog/arch_5c1051e2_1_1016792676_769419.log ORA-00280: change 395590635 for thread 1 is in sequence #769419
Specify log: {<RET>=suggested | filename | AUTO | CANCEL} CANCEL
可以看到#769419对应的redo文件是redo03.log
我们尝试恢复一下
1 2 3 4 5 6 7 8 9 10 11 12
SYS@orcl> recover database using backup controlfile until cancel; ORA-00279: change 395590635 generated at 02/06/2021 16:09:01 needed for thread 1 ORA-00289: suggestion : /u01/app/oracle/oradata/orcl/archivelog/arch_5c1051e2_1_1016792676_769419.log ORA-00280: change 395590635 for thread 1 is in sequence #769419
Specify log: {<RET>=suggested | filename | AUTO | CANCEL} /u01/app/oracle/oradata/orcl/redo03.log ORA-00279: change 395590635 generated at 02/06/2021 16:09:01 needed for thread 1 ORA-00289: suggestion : /u01/app/oracle/oradata/orcl/archivelog/arch_5c1051e2_1_1016792676_769419.log ORA-00280: change 395590635 for thread 1 is in sequence #769419 ORA-00278: log file '/u01/app/oracle/oradata/orcl/redo03.log' no longer needed for this recovery
尝试后,这种方法无法完成恢复。
我们尝试创建一个pfile文件,先把库拉起来,然后手动切换redo日志
1 2 3 4 5 6 7 8 9 10
SYS@orcl> create pfile from spfile;
File created.
SYS@orcl> shutdown immediate; ORA-01109: database not open
2 1 769421 52428800 512 1 NO CURRENT 395590691 06-FEB-21 2.8147E+14 SYS@orcl> alter system switch logfile;
System altered.
处理ORA-01012故障
数据库启动正常后,过了一会儿发现自己又停掉了
1 2 3 4 5 6 7 8 9 10 11
SYS@orcl> select status from v$instance; select status from v$instance * ERROR at line 1: ORA-01012: not logged on Process ID: 0 Session ID: 0 Serial number: 0
SYS@orcl> conn / as sysdba Connected to an idle instance.